
The Remove Duplicates transform lets you remove duplicated records by grouping all of the selected input columns and copying the results to the output.
1. Input
The Remove Duplicates transform requires one input transform.
For example, the input could be a SQL Select transform that reads data from the AdventureWorks 2012 table [Sales].[SalesOrderDetail].
2. Add the transform
To add this transform to an existing data cube process, first select the connection link between two connected transforms.
Go to the toolbar, click Insert Other, and then select Remove Duplicates.
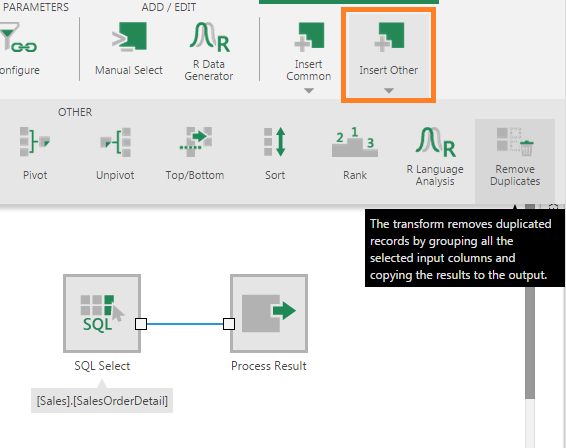
The Remove Duplicates transform is inserted between the two transforms.
3. Configure the transform
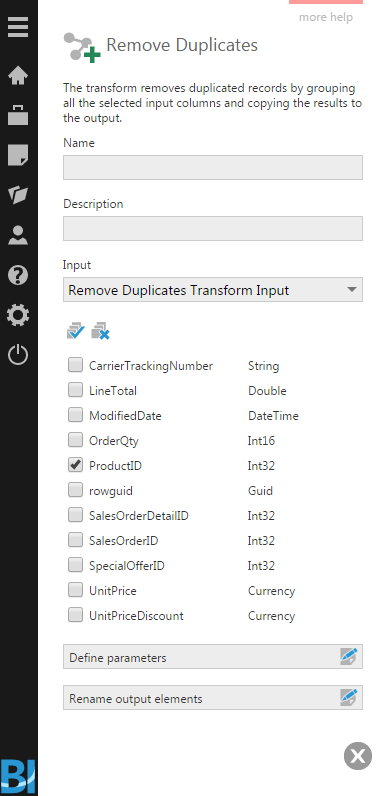
Double-click the Remove Duplicates transform, or select the Configure option from its right-click menu.
In the configuration dialog for the transform, select the input columns to be grouped and sent to the output. For example, if you simply select a ProductID column for the SalesOrderDetail table, the expectation will be that the resulting output will consist of a column of unique product IDs.
4. Output
The output of the Remove Duplicates transform consists of the column(s) you selected, where the records have been grouped in order to remove duplicates.
Select the Process Result transform and open the Data Preview to see the output of the data cube.
